Creating Rich Citation Experiences with LLMs
Citations and the user experience around them are an important component of LLM chat interfaces - they enable users to verify and cross-check information provided through RAG systems, and they build trust and usability into AI systems.
Citations can take on many forms - such as inline references or end-of-response bibliographies, and interacting with them can result in rich previews, opening new webpages, modals with information, etc..
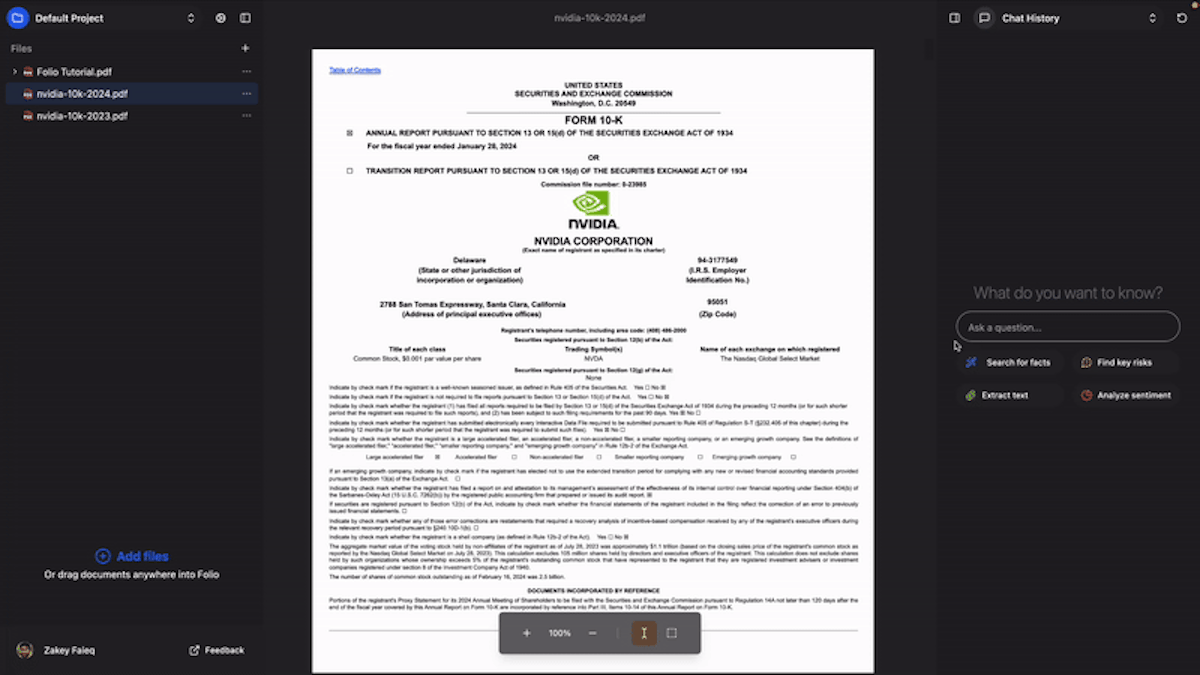
However, we're particularly excited to show an innovative new citation UX we’ve recently implemented in Folio where clicking on inline citations visually navigates to and highlights the cited text directly in the source document. This allows our users to better process key information detected by AI models.
First, we’ll go over a few simpler approaches we’ve tried for implementing citations with off-the-shelf models. Then we will review our approach to over a more complex text highlighting citation system.
Citation Types and Generation Techniques
We’ve seen citations primarily in three main styles:
- Inline citations - References intermixed within a text response
- End-of-response citations - A bibliography-style list at the end
- Combination of the above.
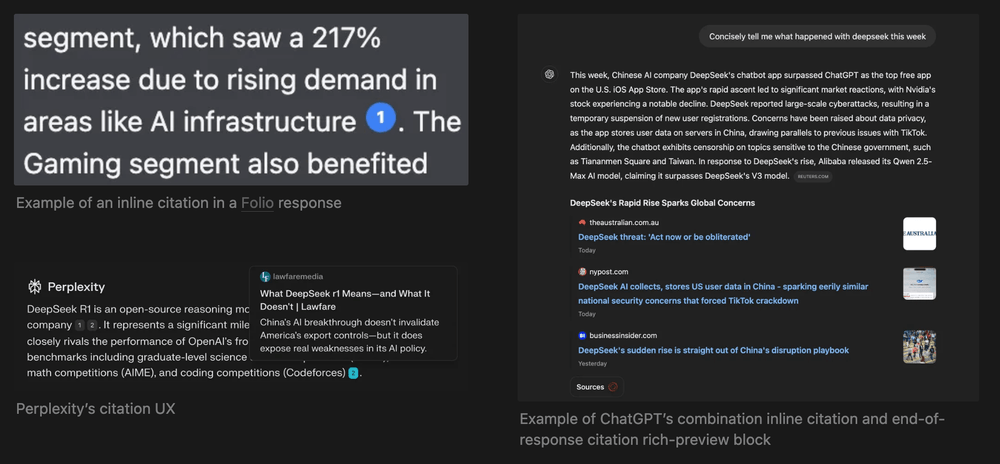
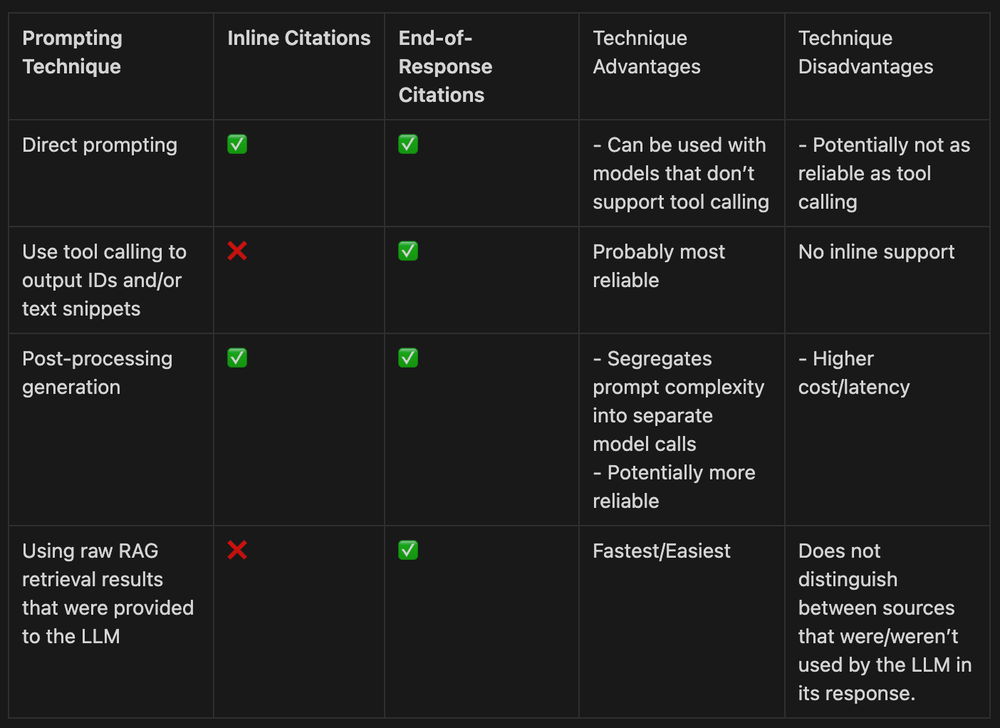
Inline citations via direct prompting is what we’ve experimented with most heavily since we do a lot of work with open source models that have poor tool calling support. We also like the UX of inline citations over end-of-response citations.
Simple Direct-Prompt Inline Citation Implementation
For basic inline citations that only need to reference document IDs from a RAG retrieval step, a straightforward prompt addition works well:
export const appendedToSystemPromptIfSourcesPresent = ` - When using information from provided sources/snippets,
cite your sources in the format [citation:id] where id is the
id number provided with the source. - Cite your sources inline within your response
(example: "It looks like [citation:id] contains information
about the code you are looking for").`;
We then parse the bracketed citations with a regex and turn them into markdown links in our UI code, which renders markdowns. When users click on the link, a preview of the chunk is shown in a modal along with a link to the original source of the chunk (code not shown).
export const parseContentAndSources = ( rawContent: string, sources: RagResult[] | undefined, ) => { const citationMap = new Map<number, number>(); const newCitedSources: RagResult[] = []; const parsedText = rawContent.replace(/\[(citation|snippet)[^0-9]
*(\d+?)]/gi, (match, type, p1) => { // Check if the captured number is within valid range (0-999) const citationNumber = parseInt(p1, 10); if (citationNumber >= 0 && citationNumber <= 999) { // First try to find by citation_id const sourceWithCitationId = sources?.find(s => s.citation_id
=== citationNumber); if (sourceWithCitationId) { let newIndex = citationMap.get(citationNumber); if (newIndex === undefined) { newIndex = newCitedSources.length; newCitedSources.push(sourceWithCitationId); citationMap.set(citationNumber, newIndex); } return `[${newIndex + 1}](#citation-${newIndex + 1})`; } return `[?](#invalid-citation)`; }); return { parsedContent: parsedText, citedSources: newCitedSources }; };
Enhanced Citations with Metadata
When citations need to include additional LLM-generated metadata
(like page numbers for PDFs, or comments/annotations that the LLM
adds to the citation), both the prompting and parsing become more complex.
Here's an example expanded prompt that elicits the LLM to generate
citations with file IDs and page numbers:
const citationInstructionsPrompt = ` If information from retrieved context is informing your response,
ALWAYS cite information in your messages like : [file_id:3-page_num:22],
[file_id:11-page_num:9], etc. based on the page number and file id of the information you are citing. ` const citationFormatExamplesPrompt = ` Correct Format: [file_id:3-page_num:22], [file_id:11-page_num:9] The following formats are NOT recommended: - Multiple citations in one bracket: [file_id:3-page_num:22,
file_id:11-page_num:9] - Page ranges: [file_id:3-page_num:11-12] - Comma-separated pages: [file_id:3-page_num:6,14,16] - Missing underscores: [fileid:3-page_num:22] or [file_id:3-pagenum:22] - Extra spaces: [file_id:3 page_num:22] - Alternative separators: [file_id:3,page_num:22] Invalid Format (will be ignored): - Missing page number: [file_id:3-page_num:] - Mixed ranges and comma-separated: [file_id:3-page_num:6-8,14,16-18] `;
Here’s some example code that defensively normalizes and parses those citations and also turns them into markdown links. (This code emerged in a whack-a-mole fashion as the LLM kept incorrectly formatting citations)
export type Citation = {
index: number;
fileId: number;
pageNum: number;
displayNum: number;
};
function processCitations(rawText: string): {
processedTextWithParsedCitations: string;
citationMap: Map<number, Citation>;
} {
const citationMap = new Map<number, Citation>();
let citationCounter = 0;
/**
* Attempt to normalize bracket contents that
might have missing underscores,
* extraneous characters, or multiple references jammed into one bracket.
* This function extracts all (fileId, pageNum) pairs it can find,
* even if the bracket is incorrectly formatted according
to the "incorrect" examples.
*/
function parseBracketedCitations(bracketContent: string): Array<{
fileId: number;
pageNum: number;
}> {
// Check if the basic citation format is correct
const citationPart = bracketContent.trim();
const isCorrectFormat = /^file_id:\d+-page_num:\d+$/.test(citationPart);
// Normalize common variations in the citation format
const normalized = bracketContent
.replace(/file[\s_]?id/gi, "file_id")
.replace(/page[\s_]?num/gi, "page_num");
const allCitations: Array<{
fileId: number;
pageNum: number;
}> = [];
// Split on commas ONLY if we detect multiple complete citations
// e.g., "file_id:1-page_num:3, file_id:1-page_num:4"
const hasMultipleCitations =
normalized.includes("file_id") && normalized.split("file_id")
.length > 2;
const referenceChunks = hasMultipleCitations
? normalized.split(",")
: [normalized];
referenceChunks.forEach((chunk) => {
const part = chunk.trim();
// Extract file_id and page_num
const fileIdMatch = part.match(/file_id:\s*(\d+)/i);
const pageNumMatch = part.match(/page_num:\s*([\d,\s-]+)/i);
// Only process if we found a valid fileId and pageNum
if (fileIdMatch && pageNumMatch) {
const fileId = parseInt(fileIdMatch[1], 10);
const pageNumStr = pageNumMatch[1];
// Handle multiple page numbers separated by commas
const pageSegments = pageNumStr.split(",").map((s) => s.trim());
pageSegments.forEach((segment) => {
// Check if this segment is a range (e.g., "6-8")
const rangeMatch = segment.match(/^(\d+)\s*-\s*(\d+)$/);
if (rangeMatch) {
// Handle page range
const startPage = parseInt(rangeMatch[1], 10);
const endPage = parseInt(rangeMatch[2], 10);
for (let p = startPage; p <= endPage; p++) {
allCitations.push({
fileId,
pageNum: p,
});
}
} else {
// Handle single page number
const pageNum = parseInt(segment, 10);
if (!isNaN(pageNum)) {
allCitations.push({
fileId,
pageNum,
});
}
}
});
}
});
return allCitations;
}
const processedTextWithParsedCitations = rawText.replace(
/\[(.*?)\]/g,
(match, bracketContent) => {
const citations = parseBracketedCitations(bracketContent);
if (citations.length === 0) {
return match;
}
let replacementStr = "";
citations.forEach((cite) => {
if (!citationMap.has(citationCounter)) {
citationMap.set(citationCounter, {
index: citationCounter,
fileId: cite.fileId,
pageNum: cite.pageNum,
displayNum: citationCounter + 1,
});
citationCounter++;
}
const storedCitation = citationMap.get(citationCounter - 1)!;
// Place citations back to back, e.g.: "[1][2]"
if multiple citations from one bracket
replacementStr += `[${storedCitation.displayNum}]
(#citation-${storedCitation.index})`;
});
return replacementStr;
},
);
return { processedTextWithParsedCitations, citationMap };
}Advanced PDF-Aware “Highlight” Citations

For one of our products, Folio, we wanted to take inline citations a step further and have the citations (on-click) actually highlight the relevant text in the original document the user was viewing.
At first this seemed like it would just be a simple extension of our existing citation format. We would just go from citations made up of the tuple containing:
[file ID, page number]to citations with
[file ID, page number, text being cited, (optional) comment/annotation]This proved to be particularly challenging because:
- The chunked RAG text being retrieved often differs slightly from the PDF.js rendered text layer.
- An LLM can make errors when generating the text it wants to highlight, or introduce ellipsis abbreviations.
Nothing a little bit of Cursor prompting couldn’t handle, right?
Problem Formulation - The key to not wasting your $$ on expensive models (e.g. o1)
We floundered for a while trying to extend the text normalization approach seen above, but the resulting indices never mapped well enough to the actual text. Claude and even o1 generated mediocre solutions when we pointed it in that direction.
The breakthrough came when we reframed the task as an approximate string matching problem and gave it a clean “leetcode problem” styled prompt with clear requirements.
Here is a cleaned up version of the prompt I provided to OpenAI’s o1 model (via Cursor) to figure out and implement the solution:
I need to implement approximate string matching to find text within a
PDF's text layer. The goal is to take a search string
(which may contain ellipses for abbreviation)
and find its exact location within the PDF page's HTML text layer.
Requirements:
1. The search string may contain ellipses ("...") to abbreviate text
2. The text must be found within a single PDF page
3. The matching needs to be fuzzy since OCR text may not match exactly
4. The solution must be fast and efficient
5. The search string could span multiple HTML elements
6. The final position needs to be exact for highlighting purposes
7. Must handle cases where the text isn't found on the page
Proposed Algorithm:
1. For text with ellipses:
- Split into prefix and suffix around the ellipsis
- Find the prefix location using approximate string matching
(Levenshtein distance) with a sliding window
- Find the suffix after the prefix location
- Use these positions to create the full highlight range
2. For text without ellipses:
- Use approximate string matching (Levenshtein distance) with a sliding
window
- Find the best matching position within a maximum distance threshold
- Convert the match position into exact DOM node and offset coordinates
3. Convert the found positions into a DOM Range:
- Map the text offsets back to specific text nodes
- Create a Range spanning from start to end position
- Generate viewport highlight coordinates for rendering
The implementation should use optimized Levenshtein distance calculation
with early exit thresholds for performance, and carefully
handle edge cases like missing text or invalid ranges.Once given the right initial direction (by mentioning “approximate string matching”) and an example of what algorithm I had in mind (Sliding window optimized Levenshtein Distance), the resulting generation from o1 was astounding.
The core is built on the Levenshtein distance algorithm, which measures how many single-character edits (insertions, deletions, or substitutions) are needed to transform one string into another.
The main search function approximateIndexOf works by:
- Taking a needle (search text) and haystack (document text)
- Sliding a window the size of the needle through the haystack
- Computing the Levenshtein distance for each window position
- Returning the position with the smallest distance below a maximum threshold
For LLM generated highlight citation text with ellipses ("..."), there's special handling in findApproximateOffsetsWithEllipsis:
- Splits the search text at the ellipsis
- Matches the prefix and suffix separately using the approximate matching
- Returns the combined range from start of prefix to end of suffix
And just like that we can now resiliently handle slight differences between our actual document text and the generated citation text! The code uses a MAX_DISTANCE of 8 for the Levenshtein Distance threshold, meaning it will accept matches that require up to 8 character edits to match exactly.
The best part is that my leetcode/DS&A skills are mediocre at best - if I tried implementing this without the help of o1, it would have taken at least a week! There may very well be a more optimal way to go about this problem, but this approach is accurate and performant enough for now.
Below is the entire generation that resulted from the prompt above:
/**
* This file provides functionality to determine bounding boxes for
* EphemeralPDFCitationHighlights given a string of text (that should be)
on the PDF page.
*/
// =============== 1) Levenshtein Distance ===============
/**
* Slightly optimized Levenshtein distance calculation using a rolling array
* and an optional early exit when distance exceeds maxDistance.
*
* @param {string} a First string to compare
* @param {string} b Second string to compare
* @param {number} [maxDistance] Optional max distance for an early exit
* @returns {number} Computed Levenshtein distance
*/
function optimizedLevenshtein(
a: string,
b: string,
maxDistance?: number,
): number {
const lenA = a.length;
const lenB = b.length;
if (lenA === 0) return lenB;
if (lenB === 0) return lenA;
let prevRow = new Array(lenB + 1);
let currRow = new Array(lenB + 1);
// Initialize prevRow for transforming empty string to b[:j]
for (let j = 0; j <= lenB; j++) {
prevRow[j] = j;
}
for (let i = 1; i <= lenA; i++) {
currRow[0] = i; // cost of transforming a[:i] to empty string
let smallestInRow = currRow[0];
for (let j = 1; j <= lenB; j++) {
const cost = a[i - 1] === b[j - 1] ? 0 : 1;
currRow[j] = Math.min(
prevRow[j] + 1, // deletion
currRow[j - 1] + 1, // insertion
prevRow[j - 1] + cost, // substitution
);
if (currRow[j] < smallestInRow) {
smallestInRow = currRow[j];
}
}
// Early exit if we exceed the threshold
if (maxDistance !== undefined && smallestInRow > maxDistance) {
return smallestInRow;
}
// Swap the rolling arrays
[prevRow, currRow] = [currRow, prevRow];
}
return prevRow[lenB];
}
// =============== 2) Approximate Index Search ===============
/**
* Attempts to find the approximate index of "needle" in
"haystack" by comparing
* each substring of length needle.length with needle under a
Levenshtein threshold.
*
* @param {string} haystack The larger string to search in
* @param {string} needle The smaller string to search for
* @param {number} maxDistance The max distance at which we
consider a match
* @returns {number}
The (approximate) start index of needle or -1
*/
function approximateIndexOf(
haystack: string,
needle: string,
maxDistance: number,
): number {
const needleLen = needle.length;
const haystackLen = haystack.length;
if (!needleLen || !haystackLen) return -1;
if (needleLen > haystackLen) return -1;
let bestIndex = -1;
let bestDistance = maxDistance + 1;
for (let i = 0; i <= haystackLen - needleLen; i++) {
const snippet = haystack.slice(i, i + needleLen);
const dist = optimizedLevenshtein(snippet, needle, maxDistance);
if (dist <= maxDistance && dist < bestDistance) {
bestDistance = dist;
bestIndex = i;
}
}
// Post-adjustment to align the first character if mismatched
if (bestIndex !== -1) {
const snippet = haystack.slice(bestIndex, bestIndex + needleLen);
if (snippet[0] !== needle[0]) {
for (let i = 1; i < Math.min(3, needleLen); i++) {
if (snippet[i] === needle[0]) {
bestIndex += i;
break;
}
}
}
}
return bestIndex;
}
// =============== 3) Ellipsis-Aware Approximate Search ===============
/**
* Handles text that may contain ellipses ("..."). This function attempts to
* match the prefix and suffix around the ellipsis separately
(using approximate)
* matching) and returns the combined bounding offsets from
prefix to suffix.
*
* @param {string} textWithEllipsis The string that may contain ellipses
* @param {string} joinedPageText The text layer string
* @param {number} maxDistance Max distance for approximate matching
* @returns {Object|null} Offsets { startIndex, endIndex }
or null
*/
function findApproximateOffsetsWithEllipsis(
textWithEllipsis: string,
joinedPageText: string,
maxDistance: number,
): { startIndex: number; endIndex: number } | null {
const ELLIPSIS_REGEX = /\.\.\./g;
const matches = textWithEllipsis.match(ELLIPSIS_REGEX);
if (!matches) return null; // No ellipses to process
if (matches.length > 1) {
console.warn(
"Multiple ellipses found. Using only first prefix and
last suffix for matching.",
);
}
// Split on all ellipses, consider first and last as prefix/suffix
const parts = textWithEllipsis.split(ELLIPSIS_REGEX).map((s) => s.trim());
if (parts.length < 2) {
console.warn("Invalid ellipsis format — no valid prefix/suffix found.");
return null;
}
const prefixRaw = parts[0];
const suffixRaw = parts[parts.length - 1];
if (!prefixRaw || !suffixRaw) {
console.warn("Ellipsis substring is missing prefix or suffix.");
return null;
}
// Approximate match the prefix from the start
const prefixIndex = approximateIndexOf(
joinedPageText,
prefixRaw,
maxDistance,
);
if (prefixIndex === -1) return null;
// Approximate match the suffix after the prefix
const suffixSearchStart = prefixIndex + prefixRaw.length;
const suffixIndexInHaystack = approximateIndexOf(
joinedPageText.slice(suffixSearchStart),
suffixRaw,
maxDistance,
);
if (suffixIndexInHaystack === -1) return null;
const suffixIndex = suffixSearchStart + suffixIndexInHaystack;
const endIndex = suffixIndex + suffixRaw.length;
if (endIndex > joinedPageText.length) return null;
return { startIndex: prefixIndex, endIndex };
}
// ============ 4) Mapping Approximate Offsets to a DOM Range ============
/**
* Converts absolute [startOffset, endOffset] in a concatenated
text layer string
* into an actual Range in the DOM.
*
* @param {Document} doc The document object to create the range
* @param {Node} root The container DOM element (i.e., textLayer)
* @param {number} start The absolute offset of the match start
* @param {number} end The absolute offset of the match end
* @returns {Range|null} The DOM Range object or null if not found
*/
function mapOffsetsToDomRange(
doc: Document,
root: Node,
start: number,
end: number,
): Range | null {
let currOffset = 0;
let startNode: Node | null = null;
let startNodeOffset = 0;
let endNode: Node | null = null;
let endNodeOffset = 0;
const walker = doc.createTreeWalker(root, NodeFilter.SHOW_TEXT);
while (walker.nextNode()) {
const textNode = walker.currentNode;
const textLength = textNode.nodeValue?.length ?? 0;
// Identify node containing 'start'
if (!startNode && currOffset + textLength >= start) {
startNode = textNode;
startNodeOffset = start - currOffset;
}
// Identify node containing 'end'
if (startNode && currOffset + textLength >= end) {
endNode = textNode;
endNodeOffset = end - currOffset;
break;
}
currOffset += textLength;
}
// If we found start but not end, just use the last node for the remainder
if (startNode && !endNode) {
endNode = startNode;
endNodeOffset = startNode.nodeValue?.length ?? 0;
}
if (!startNode || !endNode) {
return null;
}
const range = doc.createRange();
range.setStart(startNode, Math.max(0, startNodeOffset));
range.setEnd(
endNode,
Math.min(endNodeOffset, endNode.nodeValue?.length ?? 0),
);
return range;
}
// =============== 5) Creating the Highlight from a Range ===============
/**
* Constructs a ViewportHighlight from a provided DOM Range by:
* 1) temporarily selecting the Range
* 2) identifying the associated PDF pages
* 3) measuring bounding rects
*
* @param {Window} docWindow The window object
* @param {Range} highlightRange The DOM Range representing the highlight
* @param {string} text The text to store with the highlight
* @returns {ViewportHighlight|null} The created highlight
or null on failure
*/
function createHighlightFromRange(
docWindow: Window,
highlightRange: Range,
text: string,
): ViewportHighlight | null {
const selection = docWindow.getSelection();
selection?.removeAllRanges();
selection?.addRange(highlightRange);
// Identify the PDF pages from the Range
const pages = getPagesFromRange(highlightRange);
if (!pages || pages.length === 0) {
console.error("Could not identify page(s) from ephemeral
selection range.");
selection?.removeAllRanges();
return null;
}
// Measure rects in the Range
const rects = getClientRects(highlightRange, pages);
if (!rects.length) {
console.warn("No bounding rects found for ephemeral highlight range.");
selection?.removeAllRanges();
return null;
}
const boundingRect = getBoundingRect(rects);
selection?.removeAllRanges();
return {
id: `ephemeral-${Date.now()}`,
type: "text",
content: { text },
position: {
boundingRect,
rects,
},
};
}
// ────────────────────────────────────────────────────────────────────────
// Main Export: getViewportHighlightRectsForEphemeralPdfCitationHighlight
// ────────────────────────────────────────────────────────────────────────
/**
* Creates a text highlight for a given EphemeralPDFCitationHighlight by:
*
* 1) Waiting for the text layer of the target PDF page
* 2) Collecting all text from that page's layer
* 3) Handling ellipses in the highlight text, if present
* 4) If no ellipses or we fail above, using approximate matching
on the entire text
* 5) Mapping the matching offsets back to a DOM Range
* 6) Building and returning a highlight from that Range
*
* @param {Object} params
* @param {EphemeralPDFCitationHighlight} params.ephemeralHighlight
* @param {React.MutableRefObject<PdfHighlighterUtils|undefined>}
params.highlighterUtilsRef
* @returns {Promise<ViewportHighlight|null>}
*/
export const getViewportHighlightRectsForEphemeralPdfCitationHighlight =
async ({
ephemeralHighlight,
highlighterUtilsRef,
}: {
ephemeralHighlight: EphemeralPDFCitationHighlight;
highlighterUtilsRef: React.MutableRefObject<
PdfHighlighterUtils | undefined
>;
}): Promise<ViewportHighlight | null> => {
console.log("Starting ephemeral highlight creation:",
ephemeralHighlight);
const pageNum =
ephemeralHighlight.highlight.position.boundingRect.pageNumber;
const searchText = ephemeralHighlight.highlight.content.text;
if (!searchText) {
console.error("No searchText provided for ephemeral highlight.");
return null;
}
const viewer = highlighterUtilsRef.current?.getViewer();
if (!viewer) {
console.error("No viewer instance available for
ephemeral highlight.");
return null;
}
const container = (viewer.viewer as HTMLElement) ?? document.body;
const docWindow = getWindow(container);
if (!docWindow) {
console.error(
"Unable to get Window from container for ephemeral highlight.",
);
return null;
}
const doc = docWindow.document;
const maxAttempts = 50;
let attempts = 0;
// Wait for text layer to be ready
function waitForTextLayer(): Promise<HTMLElement> {
return new Promise((resolve, reject) => {
const check = () => {
attempts++;
const layer = container.querySelector(
`.page[data-page-number="${pageNum}"] .textLayer`,
) as HTMLElement | null;
if (layer) {
resolve(layer);
} else if (attempts >= maxAttempts) {
reject("Timeout waiting for text layer.");
} else {
setTimeout(check, 100);
}
};
check();
});
}
let textLayer: HTMLElement;
try {
textLayer = await waitForTextLayer();
} catch (e) {
console.error(e);
return null;
}
// Gather full text from the text layer
let joinedPageText = "";
const walker = doc.createTreeWalker(textLayer, NodeFilter.SHOW_TEXT);
while (walker.nextNode()) {
joinedPageText += walker.currentNode.nodeValue || "";
}
const MAX_DISTANCE = 8;
let startIndex = -1;
let endIndex = -1;
// Try ellipses-aware matching first
const ellipsisResult = findApproximateOffsetsWithEllipsis(
searchText,
joinedPageText,
MAX_DISTANCE,
);
if (ellipsisResult) {
startIndex = ellipsisResult.startIndex;
endIndex = ellipsisResult.endIndex;
} else {
// Otherwise, normal approximate matching
const idx = approximateIndexOf(joinedPageText,
searchText, MAX_DISTANCE);
if (idx === -1) {
console.warn(
"Could not find approximate match for ephemeral highlight text.",
);
return null;
}
startIndex = idx;
endIndex = idx + searchText.length;
if (endIndex > joinedPageText.length) {
console.warn(
"Calculated end index exceeds text length. Aborting highlight.",
);
return null;
}
}
// Convert approximate offsets to a DOM Range
const highlightRange = mapOffsetsToDomRange(
doc,
textLayer,
startIndex,
endIndex,
);
if (!highlightRange) {
console.warn("Could not map approximate offsets back to DOM Range.");
return null;
}
// Create highlight from the Range
const highlight = createHighlightFromRange(
docWindow,
highlightRange,
searchText,
);
if (!highlight) {
console.warn(
"Failed to create ephemeral highlight from approximate range.",
);
return null;
}
console.log(
"Successfully created ephemeral highlight via approximate search:",
highlight,
);
return highlight;
};
\Conclusion
Implementing rich citation experiences in LLM applications goes beyond simple references - it's about creating intuitive interfaces that help users verify information and build trust. Our new approach of highlighting cited text directly in source documents is a step forward in making AI systems more transparent and user-friendly.